
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 기본목록
- 멜론
- 크롤링
- HTML
- 딥러닝
- 머신러닝
- Selenium
- 파이썬
- 딥러닝실행
- 크롬
- while문
- 정보보호
- 주식
- 웹툰
- 도서관관리
- Visual Studio Code
- 프로젝트
- java
- 웹 크롤링
- for문
- 광주인공지능학원
- 컴퓨터보안
- 보안용어
- Python
- 딥러닝기초수학
- 딥러닝수학
- 스마트인재개발원
- 보안
- 스마트인재개발원 후기
- 문자태그
- Today
- Total
자신의 일은 스스로하자
[웹 크롤링] #2 파이썬으로 멜론 TOP100 수집 / BeautifulSoup [스마트인재개발원] 본문

✔ 멜론 차트 TOP 100을 수집해 보겠습니다.
import requests as req
from bs4 import BeautifulSoup as bs먼저 Requests와 BeautifulSoup 모듈을 import 해줍니다.
BeautifulSoup은 HTML 및 XML 문서를 구문 분석하기 위한 Python 패키지입니다. HTML에서 데이터를 추출하는 데 사용할 수 있는 구문 분석된 페이지에 대한 구문 분석 트리를 만듭니다.
2021.06.04 - [웹 크롤러] - [웹 크롤러] #1 네이버 / Melon 페이지 정보 불러오기 [스마트 인재개발원]
[웹 크롤러] #1 네이버 / Melon 페이지 정보 불러오기 [스마트인재개발원]
웹 크롤러란? 웹 크롤러(wed cralwler)는 조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램입니다. 웹 크롤러가 하는 작업을 '웹 크롤링'(web crawling) 혹은 '스파이더 링'(spidering)
oneself.tistory.com
이전 포스팅에서 말했듯이 멜론 페이지는. get() 함수로만 불러올 수 없습니다.
멜론 페이지를 불러오는 자세한 방법은 위 포스팅을 확인해 주시길 바랍니다.
h = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"}
res= req.get("https://www.melon.com/chart/index.htm",headers = h)
멜론 페이지를 불러왔다면.
soup = bs(res.text,'lxml')BeautifulSoup을 사용해 어떤 데이터를 어떻게 처리할 건지 알려줍니다. 간단히 말해 가져온 데이터에서 내가 필요한 정보들만 추출해주는 라이브러리입니다.
작성 법 ▶ bs(어떤 데이터를 처리할 건지, 어떻게 처리하는지)
원래 요청한 페이지 정보는
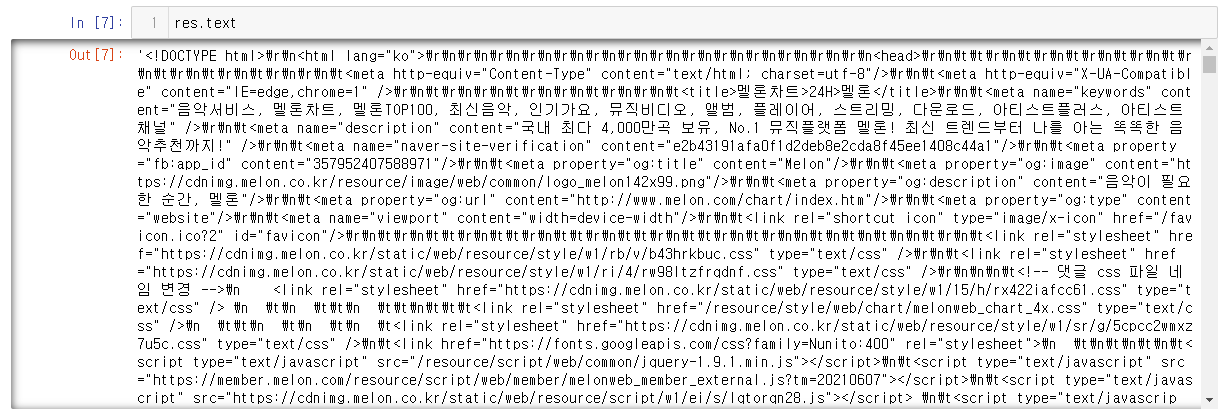
이렇게 불러졌습니다.
하지만 BeautifulSoup을 사용하면
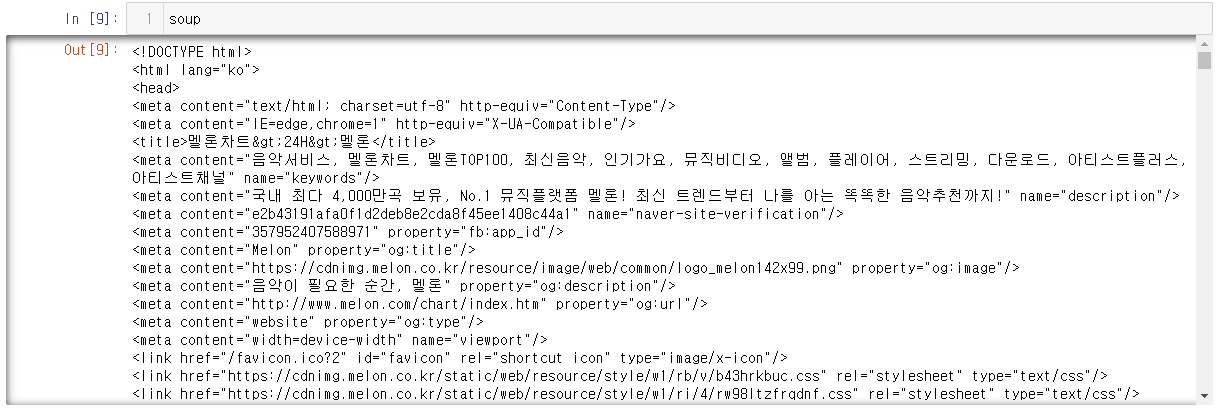
요청한 데로 res데이터를 lxml로 구분 처리해줍니다.
이제 멜론 차트 TOP 100 가수 정보와 노래 정보를 받아오겠습니다.
TOP 100 가수 불러오기
원하는 데이터를 불러오는 데는 여러 가지 방법이 있습니다. 그 중에서 . select()함수를 사용합니다.
- .select( ) : select는 CSS selector로 tag 객체를 찾아 반환합니다. CSS에서 HTML을 tagging 하는 방법을 활용한 메서드입니다.

singer = soup.select("span.checkEllipsis")
위 태그를 기준으로 lxml로 구분 처리해준 soup변수. select() 함수를 사용해 span태드 안에 checkEllipsis클래스를 넣어 가수 정보를 불러줍니다.

실행하면 TOP 100의 가수 정보를 잘 불러오는 것을 볼 수 있습니다.
리스트로 묶여있기 때문에 len()으로 길이 확인을 해보면

100개가 잘 나온 것을 확인할 수 있습니다.
아직 가수 이름 외에 나머지 정보도 같이 불러주기 때문에 고유한 이름만 불러오도록 하겠습니다.

singer변수는 리스트 형식으로 되어있기 때문에
리스트 명 [ 순서 ]. text 형식으로 적어주면 위의 결과처럼 원하는 순서의 고유한 text만 불러옵니다.
singer에 담아온 모든 가수의 text를 불러오기 위해서는 반복문을 사용해야 합니다.

for문을 사용해 위처럼 TOP 100을 불러와 줍니다.
TOP 100 노래 불러오기

song = soup.select("div.rank01>span")노래는 div라는 태그 안에 rank01 클래스의 자식 태그인 span을 받아줍니다.
※ 위의 사진처럼 클래스의 공백이 있으면 앞에 것을 제외해주고 뒤에 클래스만 사용해 줍니다.
song도 위의 singer같이 리스트로 담겨있습니다. 이를 반복문으로 돌려주면

이렇게 출력이 됩니다. 가수를 불러왔을 때와 다르게 개행 문자가 생겨 공간을 차지하는 것을 볼 수 있습니다.
이를 . strip()를 사용해 삭제해 줍니다.
- .strip( ) : 필요 없는 개행 문자(이스케이프 코드)를 삭제하는 기능

그러면 이렇게 개행 문자가 사라지는 결과를 보실 수 있습니다.
스마트인재개발원에서 진행된 수업입니다.
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr
'웹 크롤링' 카테고리의 다른 글
| [웹 크롤링] #4_2 파이썬 Selenium 모듈을 사용해 컴퓨터 제어 [스마트인재개발원] (0) | 2021.06.17 |
|---|---|
| [웹 크롤링] #4_1 파이썬 Selenium 모듈을 사용해 컴퓨터 제어 [스마트인재개발원] (0) | 2021.06.15 |
| [웹 크롤링] #3 파이썬으로 멜론 차트 TOP 100 데이터 프레임 생성, CSV저장 / pandas [스마트인재개발원] (0) | 2021.06.13 |
| [웹 크롤링] #1 파이썬으로 네이버 / Melon 페이지 정보 불러오기 [스마트인재개발원] (0) | 2021.06.04 |



